
저번 포스팅에서 가짜 뉴스앱을 만드는 과정에서 api 이슈가 있어서 다른 기능을 도입해보려고 고민한 결과 뉴스기사에서 가장 많이 사용된 단어를 노출해 주는 기능을 넣어보고자 한다.
해당 기능을 생각하게 된 이유는 뉴스기사 본문에서 가장 많이 사용된 단어가 해당 뉴스기사가 가장 전달하고 싶어하는 주제에 대한 키워드이지 않을까 생각을 하였고 이 기능을 통해 뉴스기사가 핵심적으로 전달하고 싶어하는 키워드를 쉽게 파악을 먼저 하고 뉴스기사를 읽는데 도움이 되지 않을까 싶어서이다.
가장 많이 사용된 단어를 찾기 위해서는 조사(은, 는, 이, 가,...)등을 제외하고 순수하게 단어만을 추출해야 하는데 이러한 작업은 한글 형태소 분석기를 이용할 수 있다.
한글 형태소 분석기를 찾아보니 대표적으로 사용하는 Python 라이브러로 KoNLPy가 있다고 한다.
KoNLPy에서는 Okt(구 Twitter), Mecab, Komoran, Kkma, Hannanum의 행태소 분석기를 제공하는데 각 분석기의 속도를 비교해보면 아래와 같다고 한다.
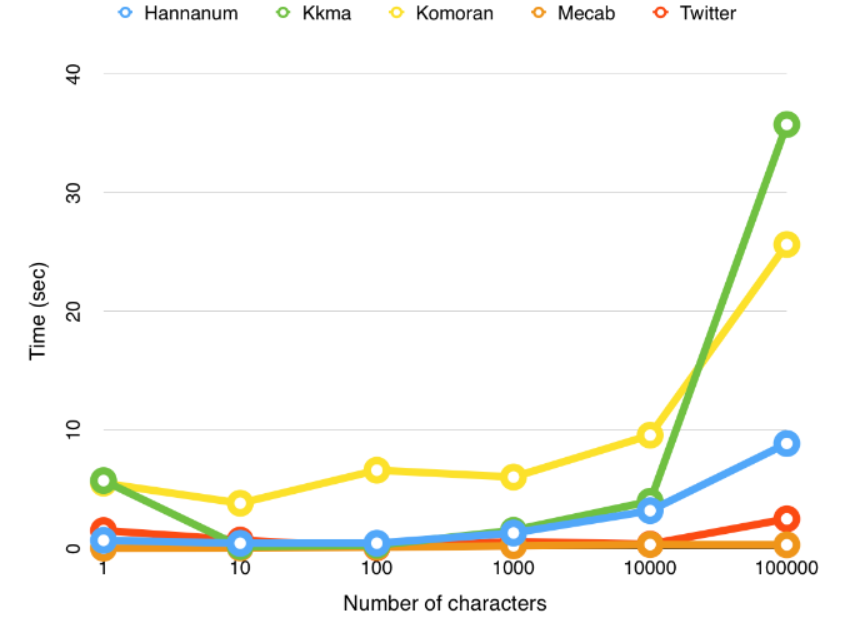
이 중에서 Mecab이 가장 처리 속도가 빨라서 해당 분석기를 기반으로 만들어진 은전한닢(seunjeon) 형태소 분석기를 이용하고자 한다.
Mecab : Kyoto Univ에서 개발한 일본어용 형태소 분석기를 한국어에 적용한 것
은전한닢(seunjeon) : mecab-ko-dic 기반으로 만들어진 JVM 상에서 돌아가는 한국어 형태소분석기, 기본적으로 java와 scala 인터페이스를 제공
mecab-ko-dic : 오픈 소스 형태소 분석 엔진인 MeCab을 사용하여, 한국어 형태소 분석을 하기 위한 프로젝트
● 참고자료
https://bitbucket.org/eunjeon/seunjeon/src/master/
Bitbucket
bitbucket.org
https://soohee410.github.io/compare_tagger
[Python] 한국어 형태소 분석기 체험 및 비교(Okt, Mecab, Komoran, Kkma)
[Python] 한국어 형태소 분석기 체험 및 비교(Okt, Mecab, Komoran, Kkma) Published Jun 07, 2020 <!-- --> 한국어는 영어처럼 띄어쓰기만으로 단어를 분리하면 제대로 되질 않습니다. 한국어는 어미와 조사 등이
soohee410.github.io
https://kaya-dev.tistory.com/20?category=791056
Tokenizer : 한국어 형태소 분석기의 종류와 사용 방법
한국어는 영어와는 다르게 토큰화(Tokenization)가 어렵습니다. 그 이유는 한국어에는 '조사', '어미' 등이 있기 때문입니다. 예를 들어, '사과' 라는 단어에 대해 조사가 붙는다고 하면 '사과가', '사
kaya-dev.tistory.com
https://konlpy-ko.readthedocs.io/ko/v0.4.3/
KoNLPy: 파이썬 한국어 NLP — KoNLPy 0.4.3 documentation
KoNLPy: 파이썬 한국어 NLP KoNLPy(“코엔엘파이”라고 읽습니다)는 한국어 정보처리를 위한 파이썬 패키지입니다. 설치법은 이 곳을 참고해주세요. NLP를 처음 시작하시는 분들은 시작하기 에서 가
konlpy-ko.readthedocs.io
'개발 > 프로젝트' 카테고리의 다른 글
| 민간복지서비스정보 공유 사이트 (0) | 2023.07.20 |
|---|---|
| 뉴스 앱 개발 - jenkins 설치 (0) | 2023.01.31 |
| 뉴스 앱 개발 - maven 설치 (은전한닢(eunjeon) sbt-pgp:1.1.0 dependency 오류 수정) (0) | 2023.01.31 |
| 뉴스 앱 개발 - 가짜 뉴스 앱 구성도 (0) | 2023.01.16 |
| 뉴스 앱 개발 - 가짜 뉴스 앱 개발 (0) | 2023.01.16 |